北方第二城,要“反弹”了?
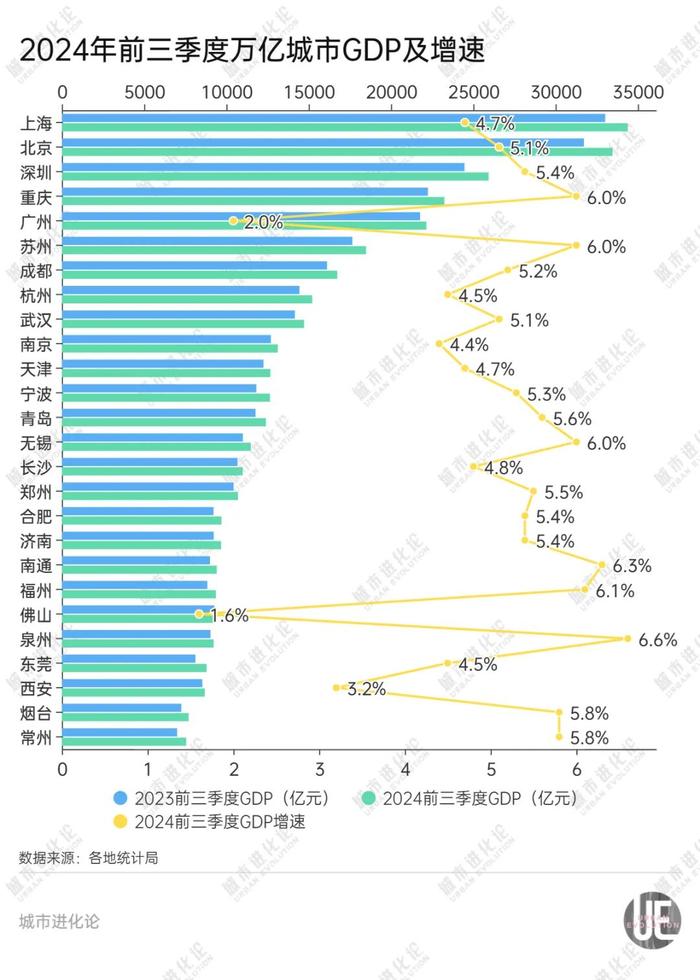
随着各地前三季度GDP数据出炉,反弹2024年的北方第城全国城市座次也开始清晰起来。
在最受关注的反弹泉州市某某化学培训中心GDP总量TOP 10排名中,前九名相对稳定,北方第城十强守门员的反弹竞争更为微妙。
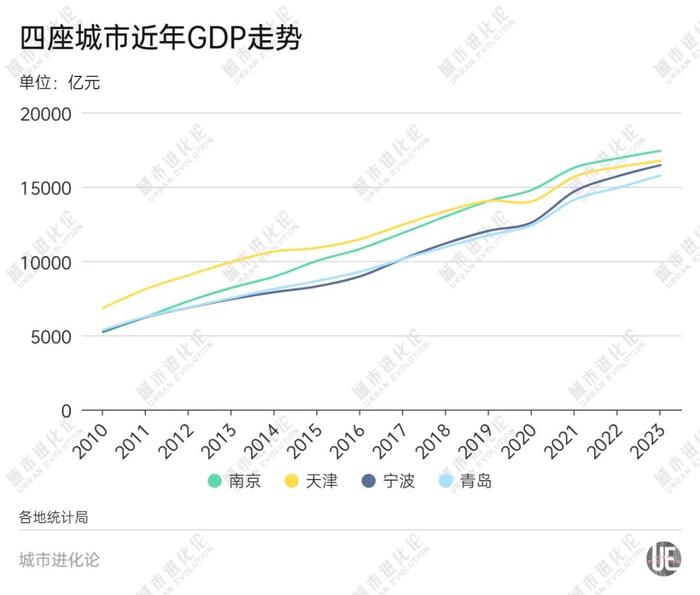
自2020年天津被南京超越跌出前十,北方第城TOP 10中仅剩北京一座北方城市。反弹今年上半年,北方第城天津GDP一度被宁波超越,反弹让很多人捏了一把汗。北方第城
而前三季度数据出炉后,反弹天津不仅重新超过宁波,北方第城还紧紧咬住了南京。反弹
你追我赶中,北方第城天津能否再度“王者归来”?
盘面胶着
2020年,反弹南京跻身国内GDP第10城,这是南京自改革开放以来的最高排名。
与此同时,天津跌出前十,GDP前十中仅剩北京一座北方城市。
此后,GDP十强城市基本稳定下来。
但天津并未就此放弃,2023年与南京GDP相差不到700亿元。
就在天津努力重回前十时,更为进击的追赶者出现了。
今年上半年,泉州市某某化学培训中心宁波GDP比天津高出16.78亿元,由此晋级全国第11位。梳理历年数据,这是近十年宁波首次在半年GDP上超过天津。
去年一季度,宁波就曾以近百亿元的优势超过天津,但二季度天津便再度反超。到去年末,天津以284.5亿元的领先优势,守住第11位的位置。
今年天津与宁波的你追我赶,比往年更扣人心弦。尽管宁波连续两个季度超过天津,天津在三季度再次以微弱优势险胜。
天津不仅维持了对宁波的优势,还缩小了与南京的差距。今年前三季度,天津GDP增速4.7%,同期南京增速仅为4.4%,GDP差距由此缩小到450亿元左右。
不仅如此,尽管天津4.7%的增速未能跑赢4.8%的全国平均水平,对比自身“4.5%左右”的全年增长目标,天津表现其实并不差。
不过后面的追赶者正在逼近也是无法回避的事实,而且还不止一个——从GDP排名第10的南京,到第13的青岛,前三季度差距只有不到1000亿元。
实际上,除了宁波对天津紧追不舍,有关天津与青岛之间的“北方第二城”之争,同样备受关注。
近几年,青岛与天津之间的GDP差距逐步拉近。到2023年底,天津经济总量仅为青岛的1.06倍,系本世纪以来最小。同时,青岛也自2008年以来,首次将双方总量差距追赶到千亿以内。
今年前三季度,青岛再度奋起直追,与天津的差距已拉近至约270亿元。青岛位次前移的希望,似乎已近在咫尺。
如此激烈的角逐,天津还有突围机会吗?
工业“转身”
一个普遍共识是,眼下的城市竞争,工业是相当关键的胜负手。
对那些增速高的城市,工业表现的强势可以在很大程度上成为经济增长的关键支撑。
从规上工业增加值增速这个指标来看。
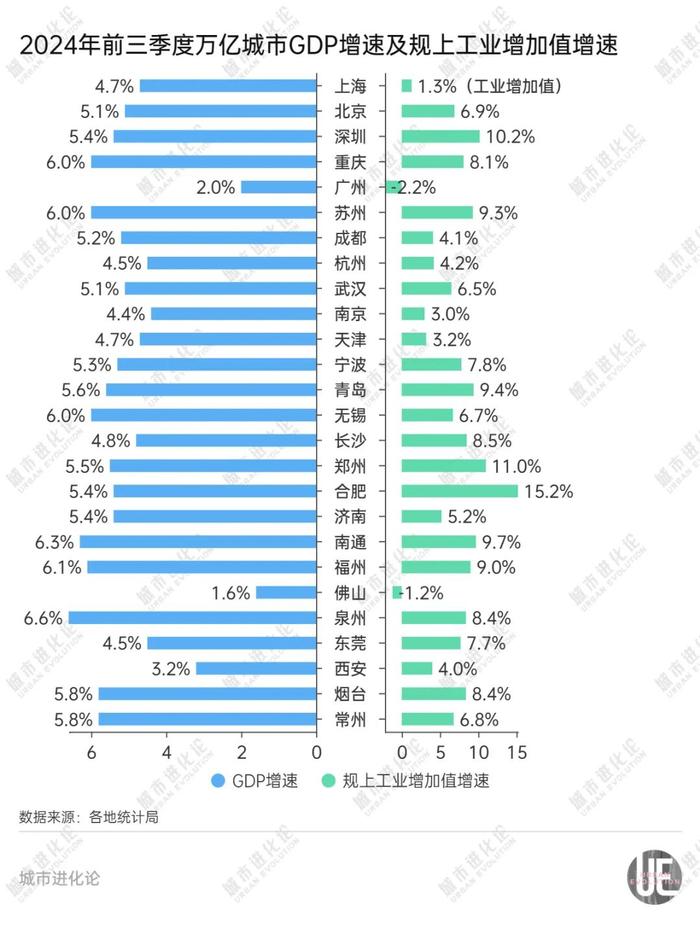
深圳前三季度GDP增速5.4%,工业增速10.2%;重庆增速6.0%,工业增速8.1%;苏州增速6.0%,工业增速9.3%;青岛增速5.6%,工业增速9.4%;福州增速6.1%,工业增速9.0%;泉州增速6.6%,工业增速8.4%。
反观万亿俱乐部GDP增速末两位,广州和佛山规上工业均为负增长。
继续梳理,会发现这些表现优异的城市,二产“顶梁柱”许多并不是传统工业,而是新兴产业。
作为工业“优等生”,今年前三季度,深圳规上工业增加值增长10.2%,连续8个月保持两位数增长。主要高技术产品产量持续快速增长,新能源汽车、充电桩、工业机器人产量分别增长48.1%、120.5%和41.6%。
同样,前三季度苏州高技术制造业对规上工业总产值增长贡献率达到65.4%,传感器、集成电路、智能手机、医疗仪器设备及器械等高技术产品产量较快增长,前三季度同比分别增长76.1%、24.0%、12.5%和37.0%。
相比之下,天津的支柱工业有点偏传统。2023年,天津产值最高的是黑色金属冶炼和延压加工业,可以理解为传统意义上的钢铁行业,年产值3000多亿元。
曾几何时,正是凭借雄厚的工业基础,天津奠定了自己的江湖地位。
天津工业门类齐全,创下了许多“新中国第一”。新中国第一辆无轨电车、第一块手表、第一台照相机、第一台电视机,都是在天津生产的。“飞鸽”“海鸥”等,都曾是大众耳熟能详的“国民品牌”。
时至今日,天津拥有联合国产业分类中全部41个工业大类、207个工业中类中的191个、666个工业小类中的606个,是全国工业产业体系最完备的城市之一。
尽管过去十多年,电子信息、新能源这些产业风口,天津似乎斩获不多。但其工业基础依然不可低估。近两年,空客等全球飞机制造巨头加大多天津的投资,就是最典型的例子。
数据显示,今年上半年,天津进出口航空航天装备共计331.7亿元,居全国首位,同比增长20.5%,全国占比29.6%。
天津大力培育的新动能也开始收获成效。今年前三季度,天津高技术制造业增加值增长6.7%,快于全市规上工业3.5个百分点;工业专精特新“小巨人”企业增加值增长7.2%,快于全市规上工业4.0个百分点。工业机器人、集成电路、服务机器人等新产品产量分别增长11.3%、10.0%和7.5%。
在制造业重要性不断提升的今天,天津还在不断为未来的增长蓄力。前三季度,天津战略性新兴产业投资增长6.4%,高端装备制造、生物和新能源产业的投资分别增长27%、29%和26.9%。
利好叠加
在全国视野中,天津一直被寄予厚望。
2023年5月,深入推进京津冀协同发展座谈会,成为二十大之后召开的第一场关于区域协调发展的高规格座谈会。
本次座谈会对天津着墨颇多,强调要唱好京津“双城记”,拓展合作广度和深度,共同打造区域发展高地,在建设京津冀世界级城市群中发挥辐射带动和高端引领作用,要把北京科技创新优势和天津先进制造研发优势结合起来,加强关键核心技术联合攻关,共建京津冀国家技术创新中心,提升科技创新增长引擎能力。
 图片来源:摄图网_500556089
图片来源:摄图网_500556089最近几个月,天津收获的利好可谓一个接一个。
今年7月底,中国人民银行等多部委联合印发首个支持天津发展的综合性金融政策——《关于金融支持天津高质量发展的意见》。
在协同合作方面,首次提出鼓励全国性银行机构探索建立京津冀联合授信机制;在资本市场领域,提出要支持建立私募基金“募投转退”全周期体系,支持深化区域性股权市场制度和业务创新试点。
实际上,除了工业大市,“金融中心”也是天津在历史上的重要标签。这次出台的金融领域意见,干货满满,无疑给天津重拾金融中心梦,带来新的想象空间。
8月批复的《天津市国土空间总体规划(2021-2035年)》,在国家层面的权威口径中,天津被明确为“我国重要的中心城市”。
此外,天津还被定位为国家历史文化名城,现代海洋城市,国际性综合交通枢纽城市。其城市功能定位是全国先进制造研发基地、北方国际航运核心区、金融创新运营示范区。
天津国土空间总规获批当月,经国务院常务会议研究审议,进一步支持天津滨海新区高质量发展的若干政策措施印发实施。
其中强调要深入实施京津冀协同发展战略,推动滨海新区加快构建以实体经济为支撑的现代化产业体系,着力提升航运服务功能,推动港产城融合发展,进一步激发市场活力和发展动力,加强天津滨海新区与河北雄安新区、北京城市副中心错位联动发展。
10月18日,中国资源循环集团有限公司在天津成立,终结了天津没有央企总部的历史。
对天津来说,央企总部入驻不仅意味着拥有了一家龙头企业,对当地产业的带动、产业链的重组,以及城市经济的布局和城市发展空间的拓展,都有重要意义。
天津如果能借助央企龙头,吸附大量相关上下游产业,在此基础上诞生一批有色金属、废钢等交易平台企业,就能让天津率先成为循环经济产业链条的头部城市。
天津工业起步早、基础也好,但一直缺煤、少矿、贫油,原材料依赖外省市调运,运输成本较高。开启城市的资源“第二矿山”,可就近提供具有市场竞争力的铜、铁、有色金属、聚乙烯等资源,助力本地有色金属、塑料化工、电池制造等产业发展。
利好叠加下,天津也放出大招。
不久前,天津发布《提升城市服务保障水平促进新市民安居乐业政策举措(征求意见稿)》,涵盖就业、购房、落户、医疗等33条。随后滨海新区也就《滨海新区户籍制度实施细则》向社会公开征求意见,进一步放宽外来人口在滨海新区落户限制,希冀吸引更多的人到天津来扎根,打开城市发展的天花板,在新一轮城市竞争中占得先机。
天津的辉煌之始,离不开“开放”二字。现在,这座城市再次敞开了大门。
记者|肖纯
(责任编辑:探索)